This week, I tested out different voices of Kokoro in two different ways:
I tested them inside Speak, within Sugar, and it worked. It still uses the hacky way of creating a temporary WAV file and then playing it via GStreamer, but it works. Streaming will be introduced soon.
Under-the-hood changes:
Kokoro currently uses the following stack:
Text → Kokoro → handle phonemes via G2P engine → Misaki (primary G2P) → fallback → Espeak-ng
Speak already uses Espeak.
So I swapped Misaki's fallback with Espeak (instead of Espeak-ng) to reduce dependencies.
I've yet to encounter a case that triggers the fallback, as Misaki is already quite good.
I deployed a web app that lets you generate and mix audio. You can try it out here.
The primary reason this was built as a web app is so that we can get kids to test this out and having things as a web app makes it easier. It's cruical for us to get real world feedback before proceeding with the implementation.
This web app allows you to try out a plethora of different voices and also mix and match different voices to create basically infinite combinations. It's truly amazing the kind of voices you can create with this.
It's a container app, meaning both the frontend (Streamlit) and backend (Kokoro - FastAPI) run as separate Docker containers hosted on Azure.
The Kokoro - FastAPI exposes an OpenAI-compatible API to generate audio.
This allows us to stream audio output to a client using OpenAI's Python libraries, like so:
fromopenaiimportOpenAIclient=OpenAI(base_url="http://my_kokoro_backend:8880/v1",api_key="not-needed")withclient.audio.speech.with_streaming_response.create(model="kokoro",voice="af_sky+af_bella",# single or multiple voicepack comboinput="Hello world!")asresponse:response.stream_to_file("output.mp3")
Another potential application of this setup (deploying as separate containers) is to bring Kokoro into pre-existing Speak with minimal dependency changes.
This would work on low end machines with a stable internet connection, as audio is generated server-side and streamed to the client.
While this wasn't in the original plan, the current architecture makes it a possibility worth exploring.
The original plan was to have an offline only version of Kokoro that Speak uses for it's voice.
Understanding and playing with Kokoro:
How voice names are read
Kokoro has a catalog of voices like af_bella or af_sky.
The first letter of the voice name indicates the language:
- a for American English
- b for British English
- j for Japanese
- m for Mandarin Chinese
- s for Spanish
- f for French
- h for Hindi
- i for Italian
- p for Brazilian Portuguese
The second letter indicates gender:
- m for male
- f for female
So af_bella would be American English, female.
Different language options:
These do two things:
1. Speak the text with an accent.
2. Handle the language-specific text more effectively.
Example: Using hf_alpha with both Hindi and English:
Input:
नमस्ते, आप कैसे हैं? I can also speak in English as well!
Output audio:
I speak Hindi, and I can confirm it sounds correct.
This is a great example of how Kokoro can help kids learning new languages by combining accent and language aware pronunciation.
Voice mixing:
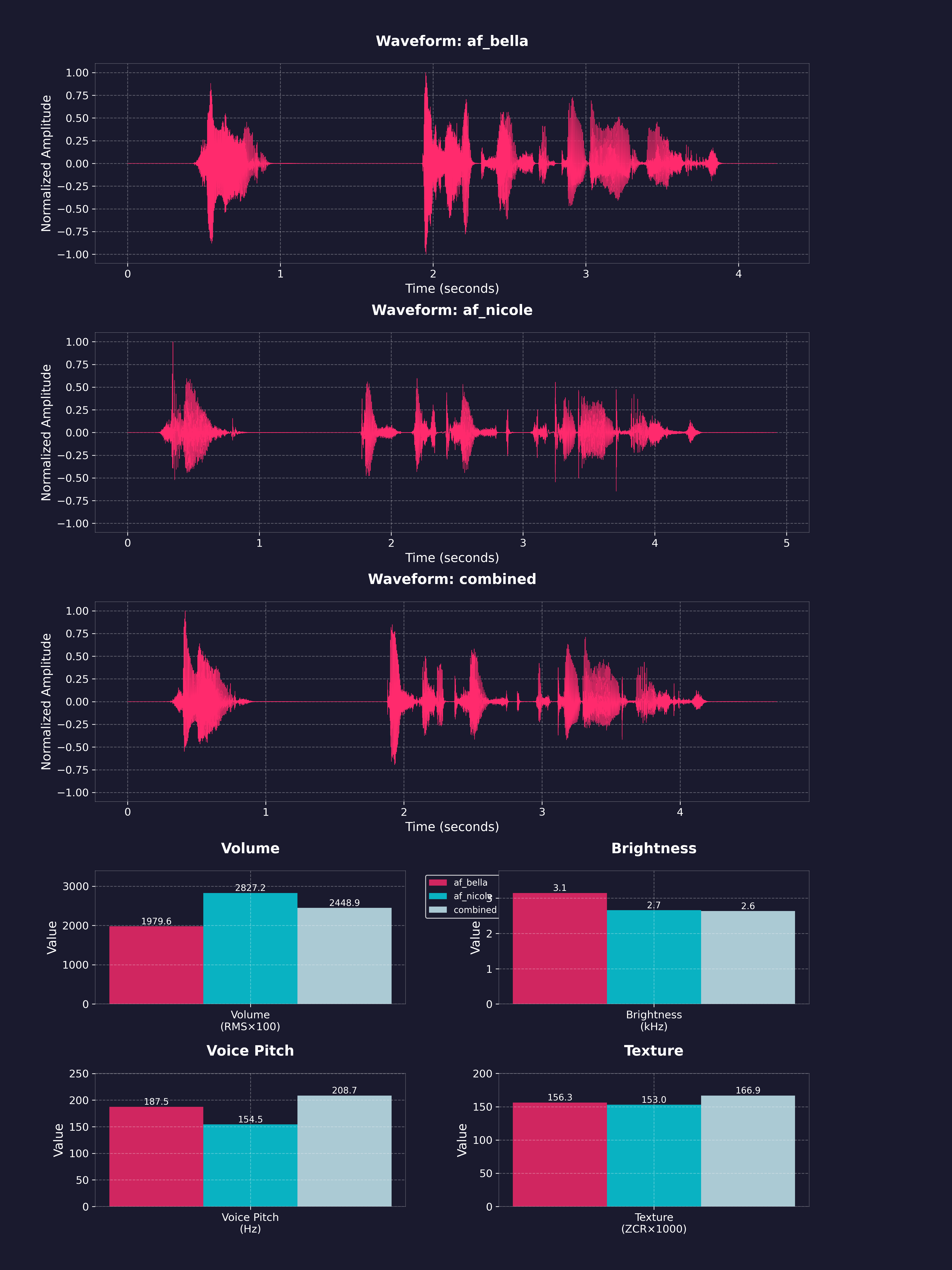
You can mix any of the available Kokoro voices.
Mixing is done by assigning weights (between 0 and 1) to each voice.
For example, mixing two voices with 0.5 weight each gives a 50-50 blend.
Mixing three voices with weights 0.6, 0.3, and 0.1 gives a 60-30-10 blend.
This allows for basically infinite voice combinations.
This could be super useful for building personas in Speak, as each persona could have a unique voice!