Goal 2: Fine-Tune a small model on a small dataset.
Goal 3: Deploy the model on AWS and create an API endpoint.
Goal 4: Test the endpoint using a python script.
Goal 5: Evaluate the model responses and think about next steps.
This Week's Achievements
Setup AWS for Fine-Tuning
Setup AWS SageMaker.
Provisioned GPUs on AWS SageMaker to fine-tune Llama3-1B foundation model.
Dataset & Cleaning
Used an open dataset. It was a dataset about conversations between a student and a teacher.
The dataset was cleaned and converted into a format that Llama needed for fine-tuning.
Wrote a small script to convert the dataset into a format that Llama can understand.
The dataset along with the script is available here.
Fine-tuning
Fine-tuned the model on a small set of the dataset, just to see how it performs and to get familar with AWS SageMaker.
The training job ran on a ml.g5.2xlarge instance.
The hyperparameters that were set so as to reduce memory footprint and mainly to test things. I'll list the hyperparameters, hoping this would serve as documentation for future fine-tuning.
The safetensors and other model files were saved in an AWS S3 bucket. The URI of the bucket is: s3://sagemaker-ap-south-1-021891580293/jumpstart-run2/output/model/
Deploying the model
The model was deployed on AWS SageMaker and an API endpoint was created.
Testing the model
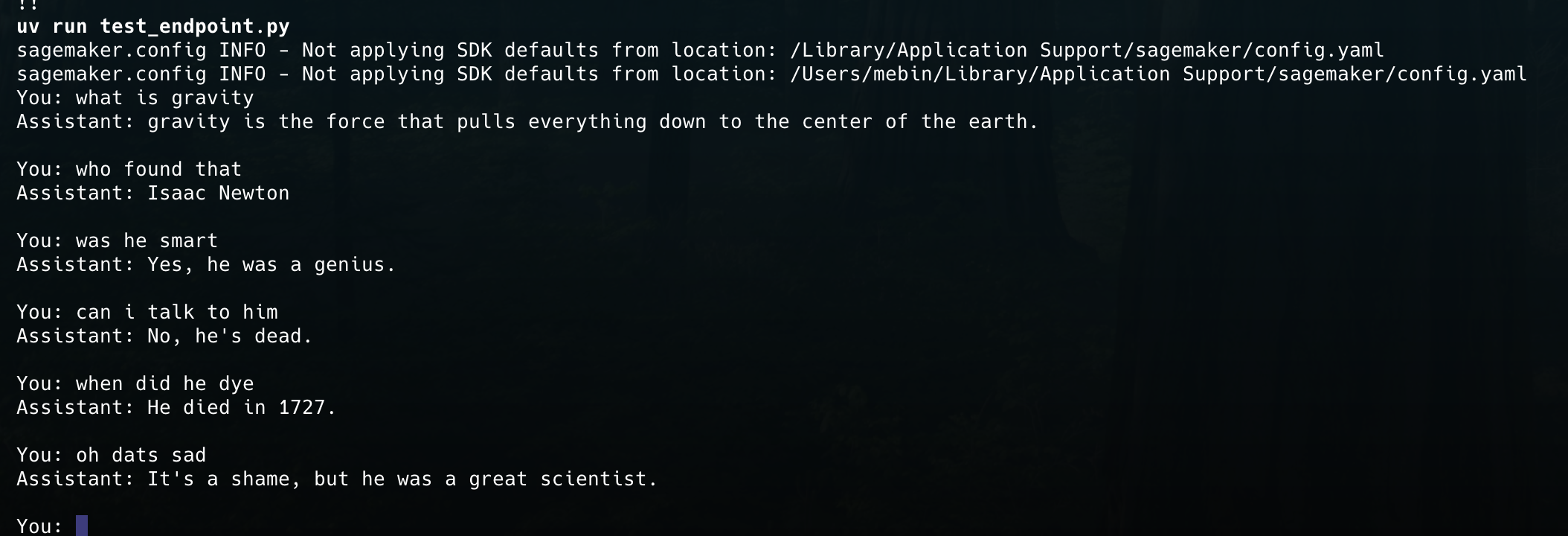
A python script was written to test the model using the API endpoint.
Evaluation
The model responses were tested using the same questions used in my benchmark done before.
Unexpected Model Output
After fine-tuning the model, I noticed that the model was producing some unexpected output. I expected the model to behave like general chatbot but in a more friendly and teacher-like manner. While the model's responses did sound like a teacher, the model would often try to create an entire chain of conversations generating the next response from a students perspective and then proceeed to answer itself.
This behaviour was becaues of the way the dataset was strucutred. The dataset was enssentially a list of back and forth conversations between a student and a teacher. So it makes sense that the model would try to create a chain of conversations. But this is not what we need from the model.
The next step is to change the strucutre of the dataset to make it just answer questions, but also to make it more conversational and understand the nuaces of a chain of conversations.
The temporary fix was the add a stop statement while generating responses and also tweaking the system prompt. But again, this is not the right way to go about it. The right was is to change the dataset structure.
Sample model output with stop condition
Key Learnings
Structure of dataset needs to be changed, in order to make it more conversational and understand the nuances of a chain of conversations.
Next Week's Roadmap
Re-structure the dataset
Re-Train and Fine-Tunethe model on the new dataset
Deploy, create endpoint and test the model on the new dataset
Evaluate the model on the new dataset and add to benchmarks
Acknowledgments
Thank you to my mentors, the Sugar Labs community, and fellow GSoC contributors for ongoing support.